
티스토리 뷰
CPU and I/O Bursts in Program Execution

프로그램은 CPU를 연속적으로 쓰는 단계와 I/O를 하는 단계가 번갈아가면서 실행됨.
CPU burst: CPU만 연속적으로 쓰는 단계.
I/O burst: I/O를 실행하고 있는 단계.
주로 사람이 interaction하는 프로그램이 중간에 I/O burst가 자주 끼어듦.
프로그램의 종류에 따라 빈도나 길이가 다름.
CPU burst Time의 분포

CPU burst가 짧고 중간에 I/O가 많이 끼어드는 job은 빈도가 높음 -> 빨간색
CPU birst가 아주 긴 job은 빈도가 낮음 -> 파란색
컴퓨터 안에는 여러 종류의 job(process)이 섞여있기 때문에 CPU 스케줄링이 필요.
- I/O bound job은 interactive job이므로 사람이 답답하지 않게 적절한 response를 제공해야 함.
- CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용해야 함.
프로세스의 특성 분류
I/O bound process
- 주로 사람하고 interactive 하는 job
- CPU를 잡고 계산하는 시간보다 I/O에 많은 시간이 필요
- many short CPU bursts.
CPU bound process
- 계산 위주의 job
- 주로 computing bound job
- few very long CPU bursts.
CPU Scheduler & Dispatcher
CPU Scheduler
- 운영체제 안에서 스케줄링하는 코드가 있음 (하드웨어 X)
- Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고름.
Dispatcher
- CPU를 누구에게 줄 지 결정한 뒤 해당 프로세스에 CPU를 넘겨주는 역할을 하는 운영체제 커널 코드|
-> CPU의 제어권을 CPU scheduler에 의해 선택된 프로세스에게 넘김. - 이 과정을 context switch (문맥 교환)라고 함.
CPU 스케줄링이 필요한 경우는 프로세스에게 다음과 같은 상태 변화가 있는 경우임.
- Running -> Blocked (예: I/O 요청하는 시스템 콜) => 자진해서 CPU를 내어놓음.
- Running -> Ready (예: 할당시간만료로 timer interrupt)
- Blocked -> Ready (예: I/O 완료 후 인터럽트)
=> 일반적으로는 I/O 끝나는 프로세스에게 바로 넘어가지 않음. 만약 이 프로세스가 priority가 가장 높은 프로세스라면 앞에 인터럽트 당한 프로세스가 시간이 남아있다하더라도 바로 CPU 넘김. - Terminated
1, 4 => nonpreemptive (강제로 빼앗지 않고 자진 반납)
2, 3 => preemptive (강제로 빼앗음)
preemptive 용어 기억하기!!
Scheduling Criteria (Performance Index, Performance Measure = 성능 척도)
시스템 입장에서의 성능 척도 -> CPU하나로 최대한 일을 많이 시키면 좋은 것.
- CPU Utilization (이용률): 전체 시간 중 CPU가 놀지 않고 일한 시간의 비율
-> CPU를 가능한 바쁘게 일을 시켜라. - Throughput (처리량): 주어진 시간 동안 몇 개의 작업을 완료했는지를 나타냄.
프로그램 입장에서의 성능 척도 -> CPU를 빨리 얻어서 빨리 끝나면 좋은 것.
- Turnaround time (소요 시간, 반환 시간): CPU를 쓰러 들어와서 다 쓰고 나갈 때까지 걸린 시간.
-> 기다린 시간 + 쓴 시간 - Waiting time (대기 시간): 기다린 시간
- Response time (응답 시간): ready queue에 들어와서 처음으로 CPU를 얻기까지 걸린 시간
-> 사용자 응답과 관련해서 중요한 시간.
*주의
여기서 "시간"의 개념은 프로세스가 시작돼서 종료됐을 때를 의미하는게 아니고, CPU 관점에서만 보기 때문에 CPU burst 건마다 따지는 것임. 즉, 프로세스가 CPU를 쓰러 들어와서 CPU를 쓰고 I/O를 하러 나갈 때까지의 시간을 의미.
스케줄링 알고리즘
FCFS (First - Come - First - Served)
- 먼저 온 순서대로 처리.
- 일단 CPU를 얻으면 내놓을 때까지 빼앗기지 않으므로 비선점형 스케줄링 (nonpreemptive)

도착 순서가 다르다면

FCFS는 앞에 어떤 프로세스가 버티냐에 따라 기다리는 시간에 큰 영향을 끼침.
*convoy effect: 긴 프로세스가 도착해서 짧은 프로세스들이 오래 기다려야 하는 현상
SJF ( Shortest - Job - First )
->CPU burst가 제일 짧은 프로그램한테 CPU를 주는 스케줄링
두 가지 방식
- Nonpreemptive: 일단 기다리는 프로세스 중에서 CPU를 제일 짧게 쓰는 프로세스에게 CPU를 줬으면 더 짧은 프로세스가 도착하더라도 CPU를 선점 당하지 않음.
- Preemptive: CPU를 줬다 하더라도 더 짧은 프로세스가 도착하면 CPU 뺏어서 그 프로세스한테 넘겨줌.
-> SRTF ( Shortest - Remaining - Time - First )
SJF is optimal
-> minimum average waiting time을 보장 => preemptive 방식일 경우에
SJF의 문제점
- CPU 사용시간이 긴 프로세스는 영원히 실행되지 않을 수도 있음. -> Starvation
긴 프로세스가 기다리고 있을 때, 끊임없이 CPU 사용시간이 짧은 프로세스가 들어온다면 영원히 실행X - CPU 사용시간을 미리 알 수 없음.
-> 추정은 가능 (과거의 CPU burst time을 이용해서 추정)
Priority Scheduling
-> 우선순위가 제일 높은 프로세스에게 CPU를 줌.
마찬가지로 두 가지 방식이 있음.
- Preemptive: 우선순위가 더 높은 프로세스가 들어왔을 때 CPU를 줌.
- Nonpreemptive: 일단 CPU를 줬으면 더 우선 순위가 높은 프로세스가 도착하더라도 다 쓸 때까지 보장해줌.
각 프로세스마다 우선순위를 나타내는 숫자가 주어짐 ( 작을수록 우선순위가 높음)
SJF도 일종의 Priority Scheduling임.
-> SJF의 경우는 우선순위를 숫자가 아닌 CPU 사용시간으로 정의하면 됨.
( priority = predicted next CPU burst time)
마찬가지로 문제점이 있음.
- Starvation
-> 우선순위가 낮은 프로세스는 영원히 CPU 얻지 못 할 수도 있음.
위 문제를 해결하기 위해 Aging 사용
-> 우선순위가 낮아도 오래 기다린다면 우선순위를 높여주면 됨.
Round Robin (RR)
- CPU 줄 때 그냥 주는 것이 아니고 동일한 크기의 할당 시간을 세팅해서 준 뒤, 시간이 끝나서 timer interrupt가 걸리면 CPU를 빼앗기고 Ready queue 제일 뒤에 가서 줄을 서는 것.
- 효율적이면서 공정한 방법
- 현대적인 컴퓨터 시스템에서 사용하는 CPU 스케줄링은 RR에 기반.
가장 좋은 점 => 응답 시간이 빠름!!
n개의 프로세스가 ready queue에 있고 할당시간이 q time unit인 경우, 각 프로세스는 최대 q time unit 단위로 CPU 시간의 1/n을 얻음.
=> 어떤 프로세스도 (n-1)q time unit 이상 기다리지 않음.
극단적인 상황
- large q
-> FCFS - small q
-> context switch 오버헤드가 커짐.
일반적으로 SJF보다 average turnaround time이 길지만 response time은 더 짧음.
특징
- 프로세스의 대기시간이 본인이 CPU를 사용하려는 시간에 비례 => 공정
- CPU 사용시간이 모두 동일한 프로그램들이 있을 땐 효율이 별로지만 대부분의 컴퓨터 시스템에서는 섞여있을 것이므로 RR 방식은 효율적이라고 볼 수 있음.
- Context (문맥)이 저장되기 때문에 이런 스케줄링이 가능한 것임.
-> 프로세스의 context를 저장하고 다시 CPU를 얻었을 때 그 지점부터 다시 재개할 수 있는 메커니즘이 제공되기 때문에 가능.
Multilevel Queue
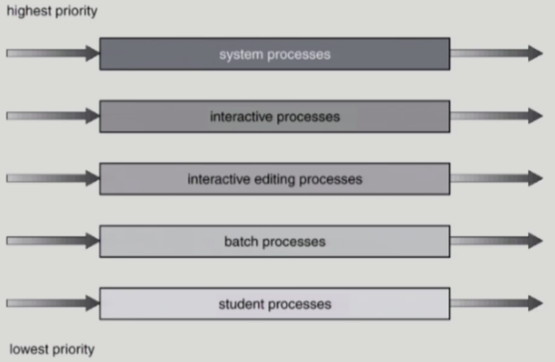
- Ready queue를 여러 개로 분할
- foreground (Interactive)
- background (batch -> no human interaction)
- 각 queue는 독립적인 스케줄링 알고리즘을 가짐
- foreground
-> 사람과 interaction하는 프로세스이기 때문에 응답시간을 짧게 하기위해 RR - background
-> 어차피 CPU만 오랫동안 사용하는 프로세스들이고 응답시간이 빠르다고 좋을게 없으므로 중간에 CPU 얻었다 뺏었다하는 context switch 오버헤드를 줄이기위해 FCFS가 효율적
- foreground
- 어떤 queue에게 CPU를 줄 지 queue에 대한 스케줄링 필요.
- Fixed Priority Scheduling: 우선순위를 강하게 적용하는 방식
(우선순위 높은 줄이 비어있을때만 낮은 줄의 프로세스한테 CPU가 감)
=> starvation 발생 - Time Slice: 각 queue에 CPU time을 적절한 비율로 할당
예) 80%는 우선순위가 높은 줄에, 20%는 우선 순위가 낮은 줄에
- Fixed Priority Scheduling: 우선순위를 강하게 적용하는 방식
Multilevel Feedback Queue
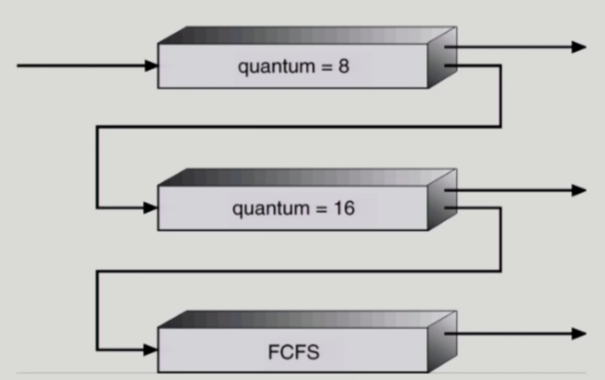
- 여러 줄로 줄서기를 하지만 프로세스가 경우에 따라 다른 queue로 이동할 수 있는 스케줄링
- Aging을 이와 같은 방식으로 구현할 수 있음.
- Multilevel Feedback Queue Scheduler를 정의하는 파라미터들
- Queue의 수
- 각 queue의 scheduling algorithm
- Process를 상위 queue로 보내는 기준
- Process를 하위 queue로 내쫓는 기준
- 프로세스가 CPU 서비스를 받으려 할 때 들어갈 queue를 결정하는 기준
- 보통 처음 들어오는 프로세스는 우선순위가 가장 높은 큐에 넣음.
- 우선순위가 가장 높은 큐는 RR에서 time quantum (할당시간)을 굉장히 짧게 줌.
- 아래 큐로 갈수록 할당시간을 점점 길게 주고 가장 아래는 FCFS.
- 할당시간이 맨 위의 큐에서 끝나게되면 그 아래로 강등.
- 따라서 CPU burst가 아주 짧은 프로세스는 도착하자마자 CPU 얻어서 바로 빠져나가고 CPU 사용시간이 좀 긴 프로세스는 맨 위 큐에서 처리가 안끝나므로 우선순위가 낮은 큐로 넘어감.
=> CPU 사용시간이 짧은 프로세스에게 굉장한 우선순위를 주는 스케줄링
Multiple - Processor Scheduling
cpu가 여러 개인 경우 스케줄링은 더욱 복잡해짐.
- Homogeneous processor인 경우
- Queue에 한 줄로 세워서 각 프로세서가 알아서 꺼내가게 할 수 있음.
- 반드시 특정 프로세서에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해짐
- Load sharing
- 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘 필요
- 별개의 큐를 두는 방법 vs. 공동 큐를 사용하는 방법
- Symmetric Multiprocessing (SMP)
- 각 프로세서가 각자 알아서 스케줄링 결정
- 모든 CPU들이 다 대등
- Asymmetric Multiprocessing
- 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따름
Real - Time Scheduling
- Hard real-time syustems
-> Hard real-time task는 정해진 시간 안에 반드시 끝내도록 스케줄링해야 함. - Soft real-time computing
-> Soft real-time task는 일반 프로세스에 비해 높은 priority를 갖도록 해야 함.
Thread Scheduling
- Local Scheduiling
- User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케줄 할 지 결정
- 운영체제는 스레드를 모름. 사용자 프로세스가 thread 직접 관리
- Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 thread를 스케줄 할 지 결정.
- 운영체제가 스레드를 알고있음.
Algorithm Evaluation (평가 방법)
- Queueing models => 굉장히 이론적인 방법
-> 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 performance index 값을 계산 - Implementation (구현) & Measurement (성능 측정)
-> 실제 시스템에 알고리즘을 구현하여 실제 작업(workload)에 대해서 성능을 측정 비교 - Simulation (모의 실험)
-> 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과 비교
* trace: 실제 프로그램에서 추출한 input data
'CS > 운영체제' 카테고리의 다른 글
| [반효경 교수님 - 운영체제] Process Management (0) | 2022.05.14 |
|---|---|
| [반효경 교수님 - 운영체제] Process (0) | 2022.05.14 |
| [반효경 교수님 - 운영체제] System Structure & Program Execution (0) | 2022.05.14 |
| [반효경 교수님 - 운영체제] Introduction to Operating Systems (0) | 2022.05.09 |
- Total
- Today
- Yesterday